
Background
Predicting train delays is anything but easy. On a route network of a good 33,000 kilometers in length with over 5,000 stations, around 13.4 million travelers were on the move every day in 2019[1]. Delays result from the interaction of circumstances such as technical disruptions, construction sites, delays in boarding and alighting, or other delayed trains. Due to the multitude and complex interaction of such influences, rule-based forecasting systems quickly reach their limits.
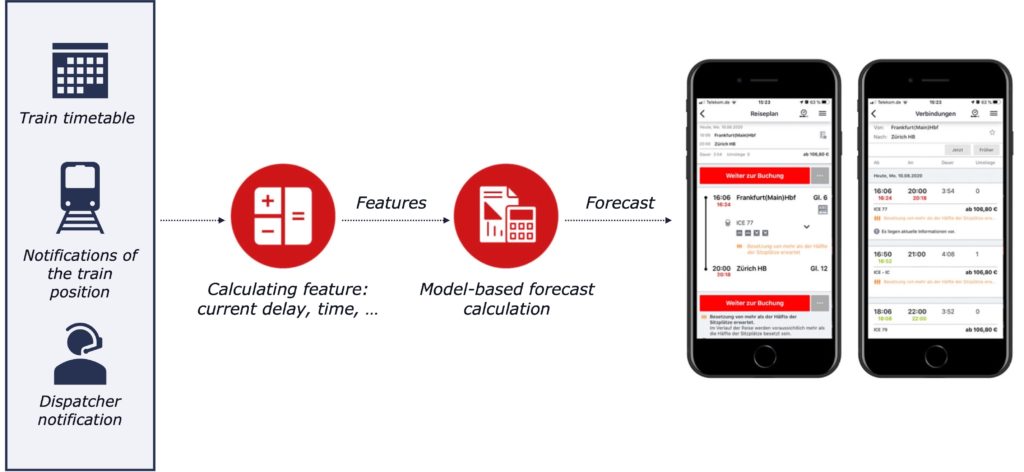
This is how the forecasts are made
As is usual in Big Data projects, a large part of the work consists of preprocessing and transforming the input data. Diversely structured raw data from a multitude of sources must be merged into a consistent data model that is filtered as much as possible to eliminate implausible or inaccurate data records that may arise, for example, in the event of malfunctions. On the basis of the clean data, influencing variables – so-called features – are then calculated which are expected to explain the delay as well as possible. Such features are, for example, the current delay at the time the forecast is generated or the travel times planned in the timetable.
The route network is divided into individual sections so that there is a measuring point at the beginning and end of each section that records the passage of a train. For each of these route sections, a machine learning algorithm learns from past data to predict the increase or decrease in delay on that route section from the measured features. The predicted total delay is then the sum of the estimated increased or decreased delays on the route sections that still need to be traversed.
This is how we develop the system
This basic procedure can be further refined. To do this, one must sometimes clarify fundamental questions first, such as: What exactly does it mean to minimize the error of the forecasts? The answer is by no means trivial. If one understands this to mean a minimum absolute error, i.e., the smallest possible average deviation of the forecast from the actual arrival or departure time, then one neglects the fact that an overestimated delay is more risky for the travelers than an underestimated one. If the system reports an early departure time, the passenger will wait longer than necessary at the platform, but if the train leaves before the predicted time, a traveler relying on the prediction may miss it. Thus, the measure of quality to which the forecast should be optimized is based on the assumption of how well passengers can live with the different types of errors.
Another area of optimization is the handling of special cases in the data. Particularly after disruptions, data flow into the forecast that result from a complex interaction between man and machine. A more differentiated consideration of such data constellations contributes to the continuous improvement of the forecasts.
Consileon also supports Deutsche Bahn in the operation and further development of a Big Data platform that processes data from sources such as timetables or train position reports within a streaming architecture in real time and provides it, among other things, to the applications for generating delay forecasts. The platform is also used to feed the forecasts into apps such as the DB Navigator app or the displays on the platform. It is based on a microservice architecture in which the individual components of the overall application can be quickly put into operation or exchanged. The cloud system was programmed with open source frameworks such as Kubernetes, Helm and Ranger. Grafana and Prometheus, among others, are used for monitoring. Throughout the project, employees of the client, Consileans and other external service providers work together in an agile manner according to the Scrum model.
[1] Deutsche Bahn – Daten & Fakten 2019
[2] https://www.openrailwaymap.org/